Modeling Empowerment
, 20180206
1
Einleitung
1.1
Perspektiven des "Empowerments"
1.2
Modellierungspraxis und Mathematik
2
Grundlagen für die Definition von Datentypen
2.1
Daten, Datentypen und Typkonstruktoren
2.2
Mengen und Gegebene Typen
2.3
Typkonstruktoren
2.3.1
Potenzmenge
2.3.2
Produkt und Schema
2.3.3
Relationen
2.3.4
Abbildungen = Funktionen
2.3.5
Listen = Sequenzen
2.4
Sprachen, Syntax und Semantik
2.4.1
Begriff und Konstruktion von Sprachen
2.4.2
Definitionen von Syntax
2.4.3
Regulärer Ausdruck
2.4.4
Deterministische Endliche Automaten
2.4.5
Kontextfreie Sprachen
2.4.6
Semantik
2.4.7
Semantische Prädikate
3
Ausblick
Bibliographie
S.F. zum Geburtstag
"Modeling Empowerment", -- was ist das denn schon wieder für ein Buzzword? Wieder mal eine imponierende Worthülse, erfunden, unerfahrene Kunden mit Kompetenz zu beeindrucken, aber letztlich doch nur ein Windkanal für heiße Luft?
Nein, ganz das Gegenteil:
"Empowerment" ist in den letzte zehn Jahren in unterschiedlichsten Kontexten (glücklicherweise) endlich ein wichtiges und ernstgenommenes Thema geworden. Es zielt darauf ab, die "reinen (L)ooser" von digitalen informationsverarbeitenden Systemen aufzuwerten zu "qualifizierten Anwendern".
Grundsätzlich beinhaltet das die Forderung, dass letztlich Programmieren eine grundlegende
Kulturtechnik ist, wie Rechnen, Schreiben, Lesen, literarische Bildung, Musizieren.
Mittelfristig ist das Erstellen einfacher Algorithmen und damit verbunden die
Kenntnis der inneren Arbeitsprinzipien elektronischer Rechner eine Erfahrung,
die jeder gebildete Mensch ansatzweise gemacht haben muss.
"Ich denke, dass die Fähigkeit zum Programmieren eine der Basisfähigkeiten junger Menschen neben Lesen, Schreiben, Rechnen wird. Diese werden nicht wegfallen, aber Programmieren wird dazukommen", so kürzlich Bundeskanzlerin Angela Merkel. [merkel]
Wir wollen hier in diesem kurzen Text mitnichten ganz so weit gehen. Hier geht es um eine viel häufigere Situation, in der noch nicht programmiert wird (oder doch?) sondern über künftige Systeme geredet, diese Systeme spezifiziert werden, oder zumindest skizziert, oder zumindest Anforderungen formuliert. All dies gehört zum Bereich der Modellierung.
Dabei geht es darum, Datenbestände, Betriebsabläufe, geschäftliche, rechtliche
oder auch dingliche, physikalische, physiologische,
oder gar soziale Verhältnisse in ein System von Datenformaten und
Verarbeitungsregeln zu übersetzen.
(In den alten Zeiten der "EDV" hieß dies "Systemanalyse".)
Wohlgemerkt, dieses System ist zunächst abstrakt, -- was davon später als digitale
Software realisiert und was manuell ausgeführt wird, ist vom Problem der Modellierung
prinzipiell unabhängig.
Ein solcher Modellierungsprozess kann nur ausgeführt werden durch die Kooperation der Fach-Experten (nennen wir sie "F") und der Modellierungs-Experten "M". Nur durch intensive Zusammenarbeit der VertreterInnen dieser meist sehr unterschiedlichen Disziplinen ist eine Modellierungsaufgabe lösbar. Das gesamte Wissen um das zu modellierende System liegt in den Köpfen der F; die notwendigen Fähigkeiten, diese ans Licht zu holen und in exakte Form zu gießen haben die M.
In den Gesprächsrunden wird dabei selbstverständlich in der Fachsprache der F über
die zu modellierende Wirklichkeit geredet werden, und die M müssen sich da hineindenken
(was diesen Beruf so abwechslungsreich macht !-)
Auch werden Begriffe und Gegebenheiten aus dem Fachgebiet der M und aus dem
weiteren Feld der konkreten digitalen Umsetzung, auf dem ja auch die F ihre
Erfahrungen haben, zur Sprache kommen.
Die wichtigste Sprache aber, die bei solchen Diskussionen immer verwendet werden muss,
ist die der Mathematik. Und zwar aus dem einfachen Grunde, weil eine dritte
Gruppe immer unsichtbar mit am Tische sitzt: die elektronischen Rechner, die zukünftigen
Arbeitspferde, und die sprechen nunmal nichts anderes!-)
Aber auch abgesehen davon (Modellierung als solche ist ja auch von Rechnern ganz unabhängig möglich) ist die Mathematik das Fundament aller Analyse und allen Austausches darüber, denn die Natur des zu erstellenden Modelles ist selbst immer eine mathematische.
Und auch in politischem Sinne ist Mathematik hier segensreich:
Fundamental für das Empowerment der F (die ja fast immer die "Kunden-Seite" vertreten,
während die M eine Dienstleistung "verkaufen") ist, sich immer gewärtig zu halten, dass
kein einziges der Buzzwords der digitalen Nerds in der Lage ist, die Grundgesetze der
Mathematik auszuhebeln. Egal welche hübsche neue Technologie mit hübschen neuen
Akronymen verkauft werden soll, -- die durch die Mathematik gesetzten Grenzen sind
unüberwindbar.
1
Fast alle der zwischen den unüberschaubar vielen kommerziellen
Systemen bestehenden Unterschiede sind rein ergonomisch. Damit immer noch wichtig genug,
aber nicht mehr vom Himmel gefallen.
Dies gilt wohlgemerkt nicht nur für technische Implementierungen, sondern auch für
die verschiedenen Modellierungsformalismen. Diese beinhalten jeweils
Rahmenwerke, Verfahrensweisen, Sprachen, graphische Systeme etc., die dazu eingesetzt
werden, einen Modellierungsprozess zu strukturieren und die Ergebnisse
für die weitere Umsetzung festzuhalten.
Wichtige Beispiele sind "Z" [spiveyZ], "OWL", "BPML", "UML" [gur].
Viele von ihnen kommen mit unterstützenden Werkzeugen, das sind interaktive
Computerprogramme
zur Editierung, Visualisierung, Typprüfung, Animation, Dokumentation etc. der verschiedenen
unterstützten Modellarten.
All diese Formalismen und ihre unterstützenden Werkzeige
sind durchaus verschieden und decken unterschiedliche Bereiche
der Modellierungsarbeit ab. Sie alle kochen aber immer nur mit dem Wasser der Mathematik,
mit dem sich zu beschäftigen also in jedweder Konstellation überaus nutzbringend ist.
Wie beruhigend!
Dieser Text beruht auf folgenden Hauptthesen:
(1)
"Mathematik", jedenfalls auf dem hier in Rede stehendem Niveau, ist
mitnichten die "Fachsprache der MathematikerInnen", sondern nichts anderes als
"in exakte Begriffe gegossener gesunder Menschenverstand".
(2)
Mit dem Entwurf der Datentypen (s.u.) sind in den allermeisten praktischen Anwendungsfällen
schon ca. 80 Prozent der operativen Möglichkeiten und Grenzen des
zukünftigen Systems festgelegt.
(3)
Wann immer eine "auffällige" Konstellation der mathematischen Konstruktoren
auftritt, weist das hin auf "Auffälligkeiten" der zu modellierenden Realität.
(4)
Jedes Mitglied der Diskussionsrunde, sei es F oder M, mit mindestens mittlerem Schulabschluss hat
fast alle für die grundlegende Modellierung notwendigen
Begriffe in der Schule kennengelernt, und war auch früher einmal
fähig, mit ihnen mehr oder weniger geschickt umzugehen.
Es ist nichts mehr als verständlich und natürlich, wenn bei den meisten F diese
Kenntnisse und Fähigkeiten mangels täglicher Anwendung inwzischen
zum großen Teil vergessen und verschüttet sind.
Sie wieder hervorzuholen ist aber kurz und schmerzlos möglich,
wie der folgende Text zeigen soll.
Er versucht, in kurzen Worten fast alle für ein Modellierungsvorhaben benötigten
Grundbegriffe der Schul-Mathematik wieder vor Augen zu führen
und mit konkreten Beispielen aus der Praxis anschaulich zu machen:
Alle darin formulierten Fragen muss ein M beantworten können, und darin formulierte
Antworten sollte ein F geben können, et vice versa.
In der praktischen Anwendung beachte man allerdings, dass auch die Mathematik (als vermeintlich exakteste Wissenschaft) auch ihre Schulen, Varianten und Vorlieben hat: es gibt durchaus leicht abgewandelte Verwendungen besonders der deutschsprachigen Begriffe: sind mit "Graphen" immer "ungerichtete Graphen" gemeint, mit "Funktionen" immer "totale" ? Diese Abweichungen betreffen aber immer Details und halten sich in engen Grenzen. Drohende Missverständnisse sollten immer durch kurzes Nachfragen schnell klärbar sein.
Folgend der obigen These (2) beschränken wir uns hier fast vollständig auf den "statischen" Anteil, die Definition der Datentypen des Modelles. Die notwendige Betrachtung der "dynamischen" Anteile, also der verschiedenen Prozess- und Ablaufmodelle (Zustandsautomaten, Prozessdiagramme, Prozesssprachen) muss einem Folgepapier vorbehalten bleiben. Allerdings behandeln wir in Abschnitt 2.4.4 ("Deterministische Endliche Automaten ") die theoretische Grundlage vieler dynamischer Modellierungsformalismen, die "Deterministischen Endlichen Automaten" in nötiger Ausführlichkeit.
Wir hoffen, damit einen konkreten Beitrag zu besserer Verständigung und höherer Effizienz und Zielgenauigkeit in Modellierungsdiskussionen zu leisten. Denn, wie gesagt, mathematische Begriffe sind nichts anderes als "in exakte Begriffe gegossener gesunder Menschenverstand". Und der sollte den M und den F gemeinsam sein.
Eine Variable ist (im weitesten Sinne) ein Speicherplatz, der mit
einem bestimmten Bezeichner eindeutig identifiziert werden kann, und der in verschiedenen
Kontexten (z.B. in verschiedenen Schritten eines Rechenablaufes oder
zu verschiedenen Zeitpunkten) unterschiedliche Werte "speichern" oder "annehmen" kann.
Dies genau, und nicht mehr, bedeutet in unserem Zusammenhang das Wort "variabel".
So sind die einzelnen Zellen einer Tabelle einer Datenbank oder
eines Kalkulationsprogrammes alle je einzelne Variablen,
ebenso die verschiedenen Eingabefelder einer Bildschirmmaske, die
einzelnen Parameter eines Programmaufrufes oder rechner-interne Register,
Rechengrößen und Hilfsspeicher.
Im allgemeineren Kontext einer Modellierung kann eine Variable aber auch als reine
Zustandsgröße benutzt werden, die mit ihren zeitlich wechselnd angenommenen
Werten einen bestimmten Schritt im zu definierenden technischen/sozialen/rechtlichen
Prozessverlauf widerspiegelt.
Wie auch immer: Allen auftretenden Variablen kann, ja sollte, jeweils ein Datentyps zugeordnet sein. Dieser (a) bestimmt die Bedeutung und (b) begrenzt den Bereich der erlaubten einzutragenden Werte.
Der Begriff des Datentyps ist in den letzten fünfzig Jahren zu einem zentralen Begriff im Bereich der Entwicklung von Programmiersprachen geworden. Im Bereich der Modellierung ist er vielleicht sogar noch wichtiger. Er beinhaltet, dass eine gegebene Größe, die als ein "Datum" betrachtet wird, z.B. die kleine ganze Zahl "5", nicht für sich alleine ein Datum ist, nicht für sich alleine irgend etwas aussagt, sondern dass sie nur in einem "Bedeutungskontext" betrachtet werden darf, eben dem "Datentyp". Ein Datentyp bestimmt immer auch einen Wertebereich (auch genannt Trägermenge). Das ist er Bereich aller möglichen Werte, den eine Variable, ein zu berechnender Ausdruck, eine Tabellenspalte, die "von diesem Typ ist", annehmen kann.
Wann immer beim Betrieb eines Systems in einem solchen Speicher ein Wert ausserhalb dieses erlaubten Bereiches angetroffen wird, ist dies ein schwerer Fehler, und die Operationalität des Gesamtsystems nicht mehr gegeben, -- jedenfalls nach den strengsten Maßstäben von "Semantik".
Statische Typprüfung bedeutet nun alle Maßnahmen (besonders bezogen auf eine Implementierung), die vor Ablauf des Systems, zu seiner Compile-Zeit mögliche Typfehler erkennen und die Implementierung als fehlerhaft zurückweisen. Je mehr statische Typprüfung, um so besser. Allerdings ist diese nicht hundertprozentig möglich. Es bleiben die Laufzeit-Typfehler, erkannt durch die Laufzeit-Typprüfung, die, wie der Name schon sagt, erst beim Ablauf der Implementierung stattfindet und zu einer entsprechenden Reaktion führen sollte.
Wird ein Fehler durch keines der beiden Verfahren erkannt, so ist wahrscheinlich das von der Implementierung letztendlich gelieferte Ergebnis fehlerhaft. Jedenfalls sind über dessen Korrektheit (im strengsten Sinne) keine Aussagen mehr möglich.
Man beachte sorgfältig, dass bei der Modellierung der Typbegriff deutlich enger
gefasst werden muss als in der später daraus abgeleiteten
technologischen Implementierung:
So muss z.B. auf der Modellierungsebene streng unterschieden werden zwischen
den "kleinen ganzen Zahlen", die einen Monat repräsentieren,
und denen, die für ein Stockwerk eines Gebäudes stehen.
In einer späteren Datenbank-Implementierung würden beide "Modell-Typen" dann
auf denselben "technischen Typ" "small-int" o.ä. abgebildet.
Wenn man diese aber bei der Modellierung schon vereinheitlicht, wäre das nur
Schlampigkeit, und man würde sich u.U. bei der späteren Umsetzung durchaus schwere
und kostenintensive Probleme einfangen.
In der Tat ist der Grad des Unterschied der Trennschärfe der Typen von der Modell- zur
Implementierungsebene durchaus verschieden ja nach Wahl der
implementierenden Infrastruktur/Programmiersprache: je moderner diese, umso trennschärfer
ihre Datentypen!
Die statischen Aspekte von Modellierung, also der Entwurf der Datensätze und ihrer
gegenseitigen Beziehungen, kann vollständig begriffen werden als Definition von
Datentypen.
Dabei wird normalerweise jedem solchen Datentyp ein Name zugewiesen,
mit dem dieser Typ referiert werden kann, um ihn in anderen Kontexten zu verwenden.
(Es kann aber durchaus auch "flüchtige" / "on the fly" Deklarationen von Typen geben,
z.B. um den Typ eines Funktionsparameters festzulegen.)
Alle handelsüblichen Modellierungsformalismen (und erst recht die Formalismen der Implementierungsebene) verfügen deshalb über (Unter-)Sprachen zur expliziten Definition von Datentypen. (Wobei viele dieser Formalismen auch implizit Datentypen definieren, z.B. wenn man in UML auch nur eine Verbindungslinie zwischen zwei Kästen zieht, etc.)
Die Konstrukton von Datentypen geschieht ausgehend von "gegebenen Typen" oder auch "given types" oder auch primitiven Typen, aus denen mittels Typkonstruktoren komplexere Typen aufgebaut werden. Wenn wir im folgenden mathematische Konstruktionen betrachten, dann entsprechen diesen auch (fast) immer Typkonstruktoren in den verschiedenen Typ-Definitions-Sprachen. Diese können durchaus verschieden heißen und sich leicht unterschiedlich verhalten, -- letztlich davon unabhängig sind aber Eigenschaften und Verhaltensweisen der durch sie lediglich unterschiedlich bezeichneten mathematischen Struktur, an der wir uns im folgenden also auch orientieren werden.
Von zentraler Wichtigkeit ist die freie Kompositionalität der mathematischen Typkonstruktoren. Diese wirklich in vielen verschiedenen Bereichen der Informatik fundamental wichtige Eigenschaft bedeutet hier, dass jeder Konstruktor auf alle beliebigen Typen anwendbar ist. Es werden also nicht nur Konstruktoren auf die primitiven Typen angewandt, sondern das Ergbnis davon ist ein neuer Typ, auf den wiederum alle Typkonstruktoren "beliebig", also "frei" angewandt werden können.
(Dem Text vorgreifend als Beispiele: Es gibt also neben Listen von Zahlen und Mengen von Zahlen immer auch Listen von Listen von Zahlen und Mengen von Listen von Zahlen, und Mengen von Mengen von Listen von Zahlen, etc.)
Wichtig bei einer späteren Umsetzung ist, dass die gewählte Technologie zur Implementierung in den meisten Fällen eine solche freie Kompositionalität nicht unterstützt, sondern bestimmte Grenzen setzt, die bei der Implementierung mit bestimmten "Tricks" dann umgangen werden müssen. Dies ist eine der wichtigsten Quellen von Fehlern, Ärger und Kosten!
Der Begriff der Menge ist, sobald man "ernsthaft" Mathematik oder Philosophie betreibt, sehr komplex und durchaus auch umstritten. In unserem Kontext reicht ein sehr vereinfachter und "rein konstruktiver" Begriff.
Dabei ist wichtig, dass die o.e. "given types", aus denen dann durch Anwendung der
Typkonstruktoren komplexere Typen gebaut werden, immer Mengen sind.
Wir müssen also immer mit Mengen beginnen.
(Ganz abgesehen davon, dass die Werte der komplexeren Datentypen immer auch als
Mengen aufgefasst werden können.)
Eine Menge ist "jede Zusammenfassung von wohlunterschiedenen Objecten unserer Anschauung
oder unseres Denkens zu einem Ganzen."
So die berühmte historische Definition durch Cantor [Cantor],
und wir wollen hier nicht in die
Abgründe der philosophischen Kritik an dieser einsteigen.
Glauben wir einfach, dass eine Menge eine derartige Zusammenfassung ist, und
dass man von jedem "gegebenen Ding", was immer das sei, sagen kann, ob es
"in einer gegebenen Menge enthalten" ist oder nicht.
Wenn ja, dann ist es ein Element der Menge.
Eines der wichtigsten Prinzipien der Mathematik ist, dass niemals mehr gilt als das was explizit gefordert wird. Eine Menge ist also wirklich nur eine "Zusammenfassung von Elementen", aber mitnichten eine "Aufreihung": sie definiert auf ihren Elementen keinerlei Reihenfolge, und jedes Element kann auch nur einmal enthalten sein, oder eben nicht.
Es gibt folgende wichtige Konstruktionen:
Eine totale Ordnung auf einer Menge sagt von je zwei Elementen aus dieser
Menge, welches von beiden das "größere im Sinne dieser Ordnung" ist.
Man beachte die typisch mathematische Vorgehensweise: eine "Ordnung" ist ein
neues mathematisches Objekt, das zu der Menge hinzutritt. Es ist also nicht eine
"geordnete Menge", wie man so gerne sagt, sondern "eine Menge PLUS eine Ordnung".
Das ist unter Umständen wichtig, da es ja "eine Menge PLUS mehrere Ordnungen" geben kann:
Die Menge der MdB hat die Ordnung des Lebensalters und die des Dienstalters,
und wer die Eröffnungsrede hält ...
(Neben den totalen gibt es auch "partielle Ordnungen", aber das führt hier erstmal zu weit.)
Eine endliche Menge liegt vor, wenn die Anzahl dieser Elemente endlich und bekannt ist.
Ein Aufzählungstyp ist eine sehr häufige Variante des primitiven Typs. Sein Wertebereich ist eine endliche Menge, von der alle Elemente bekannt sind. Jedes von ihnen hat einen Namen, unter dem es referiert werden kann. Diese Namen werden vom Autor des Datentyps explizit vergeben.
(Die folgenden Beispiele folgen einer freien "Fantasie-Syntax", die sich aber eng an der Schreibweise der Mathematik orientert und somit auch den Datendefinitionssprachen in fast allen Modellierungsformalismen entspricht. Ähnlich wie die Grundkenntnisse selbst sollten auch die Schreibweisen der mathematischen Sprache tief im Mittelstufen-Unterbewußten jeden Lesers noch abgespeichert sein !-)
Ein erstes einfaches Beispiel ist die Definition
Wochentag = { Mo, Di, Mi, Do, Fr, Sa, So }
|
Ob mit der Definition eines Aufzählungstyps auch implizit eine Ordnung vergeben wird, ist durchaus fraglich. Rein mathematisch ist das nicht der Fall, in obiger Schreibweise deuten die "Mengenklammern" an, dass diese Definition exakt identisch wäre mit
Wochentag = { Di, Do, Fr, Mi, Mo, Sa, So }
|
Viele Modellierungsformalismen aber bieten eine Syntax an, die beides in einem Zuge definiert, also die Mengen-Elemente und eine Ordnung auf diesen. Rein mathematisch aber wären das zwei verschieden Schritte. Gerade beim Übertragen von einem Modellierungsformalismus auf ein anderes können sich solche impliziten Definitionen unbemerkt ändern.
Noch gefährlicher sind implizit definierte Codierungen in den natürlichen Zahlen, wie "Mo=0", "Di=1", ..., die von vielen Formalismen stillschweigend eingeführt werden. Diese sollten auf der Modellierungsebene keinesfalls benutzt werden, sondern stattdessen immer nur die explizit vergebenen Namen. (Dafür sind sie ja da !-)
Eine unendliche Menge ist eine solche, für die es für jede beliebig großen endliche Teilmenge immer ein Element gibt, was in der Menge aber nicht in dieser Teilmenge ist.
Häufiges Beispiel sind die natürlichen und die ganzen Zahlen:
N = { 1, 2, 3, 4, 5, ...}
Z = { ..., -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, ...}
|
Beide gehören zu den "vordefinierten primitiven Typen", die fast immer zur Verfügung stehen. Auf beiden ist die normale, bekannte Ordnung "<" definiert.
Manche Modellierungsformalismen unterstützen nur Z aber nicht N.
Andere hingegen erlauben, beliebige Untermengen zu definieren und diese als Wertebereiche von Datentypen zu verwenden. Besonders häufig sind dabei Ausschnitte, deren Konstruktion sich auf eine Ordnung stützt, wie
T = { 1 .. 7 } = { n ∊ N | 1 <= n <= 7 }
|
Wichtig ist, dass beim Übergang vom Modell auf die Implementierung fast immer
der unendliche Datentyp durch einen endlichen realisiert wird, wie "big-int", o.ä.
Auch das kann spätere Umsetzungs- oder Laufprobleme bereiten.
(Es gibt allerdings in der Tat Implementierungen mit unbegrenzt großen
Wertebereichen wie BigDecimal in Java, aber die werden selten verwendet.)
Setzen wir eine "Standard-Ordnung" voraus, und sei dies die bekannte "<".
Dann sind die Mengen/Wertebereiche/Datentypen von N (Z) unendlich, weil es im Sinne dieser Ordnung zu jeder Zahl immer eine größere (eine größere und eine kleinere) gibt. Aber jeder beliebige beidseitig begrenzte Ausschnitt (im Sinne dieser Ordnung) ist hingegen endlich. Solche Mengen heißen auch diskret.
Im Gegensatz dazu gibt es dichte Mengen. Bei diesen liegen
in jedem beliebig begrenzten Ausschnitt unendlich viele weitere Elemente.
Man kann auch sagen: "zwischen" (=im Sinne dieser Ordnung)
zwei beliebig ausgewählten Elementen liegt immer mindestens ein weiteres.
Diese sind also nicht (nur) "nach oben und unten unendlich", sondern auch "nach innen".
Beispiel sind die Rationalen Zahlen Q, die bekannten "Bruchzahlen", und die Dezimalbrüche R.
Auch hier gilt, dass i.A. eine Implementierung nur endliche Wertebereiche zur Verfügung stellt. Diesmal ist die Begrenzung aber nicht nur "nach oben und unten", sodern auch bezogen auf die "Genauigkeit", die "Nachkommastellen". Auch dies kann beim Übergang vom Modell zur Implementierung durchaus Probleme bringen.
Das sind aber schon i.A. alle gegebenen Datentypen. Mit den Aufzählungstypen, den Ganzen Zahlen und einem der dichten Zahlentyp kommt man fast immer aus! Das ist doch schon sehr beruhigend.
Es kann noch dazukommen ein Boolscher Typ
B = { false, true }
|
Dieser ist i.A. nichts anderes als ein Aufzählungstyp. Sobald aber "Boolsche Logik" ins Spiel kommt, kann es sein, dass seine Werte anders behandelt werden als normale benutzerdefinierte Aufzählungstypen.
Wie oben erwähnt dienen Typkonstruktoren dazu, aus gegebenen Typen einen
komplexeren Typ zusammenzusetzen. Diese zusammengesetzten Typen werden benötigt,
um bestimmte Konstellationen der Wirklichkeit im Modell abbilden zu können.
Interessanterweise sind dazu recht wenige und sehr einfache Konstruktoren erforderlich.
Von diesen könnten die hier letztgenannten (Funktion, Liste, s.u.)
sogar noch auf die erstgenannten zurückgeführt
werden; sie sind also rein mathematisch nicht erforderlich, aber ergonomisch durchaus
förderlich.
Betrachten wir nun diese Typkonstruktoren anhand von praktischen Beispielen.
Ein erster und sehr wichtiger Typkonstruktor ist die Potenzmenge
oder auch "Power Set".
Wenn der Typ "T" eine Menge M als Wertebereich hat, dann hat "POW T"
als Wertebereich die Menge aller Teilmengen von M.
Beispiel:
VAR heute : Wochentag
VAR kantineOffen, büroZugänglich : POW Wochentag
heute = Do
kantineOffen = { Mo, Di, Mi, Do, Fr }
büroZugänglich = { Mo, Di, Mi, Do, Fr, Sa }
|
"Wochentag" sei der oben definierte Aufzählungstyp.
Es werden drei Variablen mit den Namen "heute", "kantineOffen" und "büroZugänglich" deklariert.
Die Schreibweise mit dem Doppelpunkt bedeutet in fast allen Modellierungsformalismen
eine Typangabe: Die Variable "heute" ist vom Typ "Wochentag", kann also als Wert nur einen Wert
aus diesem Aufzählungstyp annehmen.
Hingegen sind "kantineOffen" und "büroZugänglich" vom Typ "POW Wochentag"; sie können jeweils
eine Teilmenge des Wertebereiches des Aufzählungstyps annehmen.
(Hat die Menge "M" n Elemente, dann hat "POW M" 2^n Elemente, da jedes Element enthalten sein kann oder auch nicht. Daher kommt auch der Name "Potenzmenge".)
(Man beachte dass die leere Menge ein möglicher Wert für jeden Potenzmengentyp ist!)
Macht eine Behörde einen Rahmenvertrag mit einem Caterer für verschiedene Kantinen, dann kann darin z.B. stehen, welche Öffnungszeiten u.U. angefordert werden können:
VAR möglicheZeiten : POW POW Wochentag
möglicheZeiten = { {Mo, Di, Mi, Do, Fr}, {Mo, Di, Do, Fr},
{Mo, Di, Mi, Do, Fr, Sa} }
|
Dies ist ein Beispiel für o.e. Kompositionalität der Typkonstruktoren: der Wertebereich der Variablen "möglicheZeiten" sind Mengen von Mengen von Wochentagen.
Ein zweiter grundlegender Typkonstruktor ist das Produkt. Die Werte eines Produkttyps heißen Tupel.
Die Werte des n-stelligen Produktes heißen auch n-Tupel. Grundlegend ist das zweistellige Produkt, dessen Werte auch Paare heißen. Alle mehrstelligen Produkte können durch geschachtelte zweistellige realisiert werden.
Ein z.B. drei-stelliger Produkttyp A*B*C hat als Wertebereich
alle möglichen Kombinationen von drei Werten, wobei der erste vom Typ A, der zweite
vom Typ B und der dritte vom Typ C ist.
Eine solche Kombination wird als "Drei-Tupel" realisiert und mit Kommata und
runden Klammern geschrieben, also "(a,b,c)".
Dabei ist die Reihenfolge signifikant: der Typ des k-ten Tupel-Bestandteiles ist
genau der k-te Typ im Typausdruck.
Aber auch wenn die Typen identisch sind, ist die Reihenfolge der Werte signifikant,
wenn sie verschieden sind:
der Wert (a1,a2) vom Typ A*A ist dann ein anderer als (a2,a1).
Beispiel:
jahreszahl = N
monatsname = { jan, feb, mar, apr, mai, jun, jul, aug, sep, okt, nov, dez }
tagimmonat = { 1 .. 31 }
kalendertag = jahreszahl * monatsname * tagimmonat
VAR heute : kalendertag
|
Dieses einfache Beispiel zeigt bereits, wie stark die Einschränkungen sein können, die eine banale Typdefinition dem späteren Gesamtsystem unumgehbar und für seine ganze Lebenszeit aufzwingen kann: Sollen auch Jahreszahlen "vor Christus" modelliert werden, dann wären dafür negative Zahlen die kanonische Darstellung und die Definition müsste "jahr = Z" heißen.
Dieses Beispiel zeigt auch, dass Modellierung immer nur eine Annäherung an die Wirklichkeit sein kann: die Datendefinition verbietet keinesfalls den Wert (2017, feb, 30). Rein typtechnisch ist dies ein korrekter Wert!
Eine Menge von Werten von Tupeln wird z.B. häufig dargestellt als Zeilen einer Tabelle: jede Spalte entspricht einer Position des Tupels; alle Werte einer Spalte haben denselben Typ; jede Komponente jedes Tupels kann als eine eigene Variable betrachtet werden.
(Ein Tupel kann aber auch oft als eine Art von Objekt im Sinne der "objektorientierten Programmierung" betrachtet werden. Dann wäre jede einzelne Komponente eines Tupels ein "Feld" dieses Objektes und kann wiederum als je eine eigene Variable angesehen werden.)
Erst einmal nichts anderes als Tupel, aber etwas bequemer im Umgang sind Schemata. Diese sind in ihrer einfachsten Gestalt nichts anderes Tupel mit benannten Komponenten. Eine der historisch wichtigsten und methodisch saubersten Sprachen, für die Schemata zentral sind, ist wohl "Z" [spiveyZ]. In deren Syntax hieße obiger Datentyp als Schema ausgedrückt
+---- kalendertag --- | jahr : jahreszahl | monat : monatsname | tag : tagimmonat +-------------------- |
Wir schreiben in folgenden einfach
kalendertag = jahr:jahreszahl * monat:monatsname * tag:tagimmonat |
Tatsächlich sind Schemata (jedenfalls in dieser einfachen Version) nichts anderes als Tupel, nur dass die Identifizierung der Komponenten durch ihre bloße Reihenfolge ersetzt ist durch ihre Identifizierung qua Namen, was für menschliche Leser und Autoren den Umgang einfacher und weniger fehleranfällig macht.
Typisch für Z (und andere schema-basierte Typformalismen) ist aber ein leicht weiterentwickelter Begriff von Schema. Darin kann die Menge der erlaubten Werte durch hinzugefügte logische Bedingungen eingeschränkt werden:
+---- kalendertag ---
| jahr : jahreszahl
| monat : monatsname
| tag : tagimmonat
+--------
| monat ∊ {jan, mar, mai, jul, aug, okt, dez} OR tag < 31
| monat == feb ==> tag < 30
+--------------------
|
Diese Typdefinition ist schon "näher an der Wirklichkeit". Hier ist im Ggs. zu oben "(jahr=2017, monat=feb, tag=30)" schon rein typ-technisch kein erlaubter Wert.
Aber immernoch gibt es Differenzen zur Wirklichkeit:
die Bedingung für eine gültige Tageszahl im Februar
müsste eigentlich die Schaltjahre berücksichtigen.
Dies ist aber relativ aufwendig, und die Frage muss gestellt werden, ob
dieser Aufwand vom letztendlichen Zweck der Modellierungstätigkeit gefordert wird.
Selbst wenn dies berücksichtigt würde, gäbe es weitere fehlende Aspekte, wie die
verschiedenen Umstellungen von Julianisch auf Gregorianisch, etc.
Der Aufwand und die Detailgetreue einer Modellierung muss immer durch ihren
letztendlichen Zweck bestimmt werden: die Wasserversorgung in Klein-Machnow
für die nächsten zwanzig Jahre erhebt andere Anforderungen als die
Katalogisierung vorchristlicher Tontafeln, -- schon bei den vermeintlich
trivialsten Datentypdefinitionen.
(Analog zum Produkt gibt es noch die (Typ-)Summe. Diese bedeutet eine Auswahl aus verschiedenen Varianten, also Typen, deren Wertebereiche "zusammengeworfen" werden. Summen werden (a) nicht so häufig benötigt und (b) in der Implementierung eh durch Produkte ersetzt, also hier erst einmal nicht weiter besprochen.)
Ein fundamental wichtige Familie von Datentypen entsteht nun durch die Kombination von Produkt und Potenzmenge.
person = { Abel, Berthold, Casalla }
abteilung = { Kundenbetreuung, Lager, Manufaktur }
erfahrung = POW (person * abteilung)
VAR kennt : erfahrung
kennt = { (Abel, Kundenbetreuung), (Abel, Lager),
(Berthold, Lager), (Berthold, Manufaktur) }
|
Der Wertebereich des Datentyps "erfahrung" besteht aus allen möglichen
Mengen von Paaren aus "person" und "abteilung".
Ein solcher Wert (also eine bestimmte solche Menge von Paaren) ist der momentane
Wert der Variablen "kennt".
Modelliert wird damit, welcher Mitarbeiter in welcher Abteilung jemals gearbeitet hat
oder zur Zeit arbeitet.
Diese Art von Datentyp ist ein förmliches Zaubermittel in der Modellierung, mehr aber noch in der Implementierung. Seine mathematischen Eigenschaften sind von wunderbarer Einfachheit, seine Anwendbarkeit hingegen universell. Die Entdeckung seiner Möglichkeiten [Codd] war einer wichtigsten Meilensteine in der Entwicklung der automatisierten Datenverarbeitung. Erwähnte Einfachheit ist nämlich nicht nur eine Quelle großer ästhetischer Schönheit der Rechengesetze und tiefer Befriedigung beim Betrachter, sondern führt auch ganz konkret zu effizient formulier- und ausführbaren Verarbeitungsprogrammen.
Spätestens hier, aber auch schon vorher, im Bereich der theoretischen Mathematik,
hat diese Familie von Datentypen einen eigenen Namen verdient und heißt
Relationstyp.
Man kann also abkürzend schreiben
R = POW (A * B) = REL(A, B) = A <-> B |
Jeder konkrete Wert aus dem Wertebereich des Relations-Typs R (z.B. jede momentane Wert einer Variablen vom Typ R) ist also eine Menge von n-Tupeln, deren Komponenten vom Typ A und B sind. Dieser Wert heißt auch Relation (im Sinne von "Wert von einem Relations-Typ", -- es gibt auch abkürzende Sprechweisen, die den Typ selber "Relation" nennen!)
Diese Mengen von n-Tupeln können nun bestimmte Relations-Eigenschaften haben.
Es ist nun häufig sinnvoll für einen Relationstyp R, der ja bestimmte
Eigenschaften der Wirklichkeit wiedergeben soll, seinen
Wertebereich einzuschränken auf die Mengen von Tupeln mit einer bestimmten Relations-Eigenschaft.
Um diesen sehr wichtigen Bereich genauer zu diskutieren, kann es hilfreich sein, sich die Relationen graphisch vorzustellen.
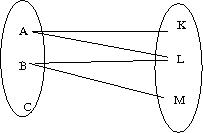
Beginnen wir mit obigem Wert "kennt":
In dieser Standard-Darstellung einer zweistelligen Relation "T<->U", also eines bestimmten Wertes vom Relationstyp "T<->U", sehen wir links und rechts die Wertebereiche der Typen T und U. Jeder Verbindungsstrich zwischen zwei Elementen steht für ein 2-Tupel, das in der Relation enthalten ist.
(In diesem Zusammenhang sei daran erinnert, dass eine "Menge" jedes Element nur maximal einmal enthalten kann: jede mögliche Kombination aus T und U ist entweder enthalten oder nicht. Es gibt in der graphischen Darstellung also zwischen zwei Elementen aus T und U maximal eine Verbindungslinie.)
Was an der Graphik sofort auffällt: sie ist nicht links-total.
Nicht jedes Element in T (hier = "person") ist Ausgangspunkt einer Linie.
Die Bedeutung des Wertes "kennt" soll ja sein, dass eine Person in einer Abteilung
arbeitet oder gearbeitet hat. Dann muss also "C" ein ganz neu eingestellter Mitarbeiter sein,
dessen Repräsentant im Datenmodell gerade erst hinzugefügt worden ist, bevor sie/er
irgendwo gearbeitet hat.
Hingegen ist die Relation rechts-total, also in jeder Abteilung kommt eine Verbindungslinie an, hat also mindestens eine Person jemals gearbeitet. Auch das ist nicht selbstverständlich, z.B. in einer Gründungsphase. (Bei manchen Abteilungen bleibt der Zweifel ...!-)
Die Relation ist auch nicht links-eindeutig. Links-eindeutig bedeutet, dass "der Blick nach links" eindeutig ist, also an jedem Element der Zielmenge U nur maximal eine Linie nach links beginnt.
Die Relation ist auch nicht rechts-eindeutig. Rechts-eindeutig bedeutet, dass "der Blick nach rechts" eindeutig ist, also an jedem Element der Menge T nur maximal eine Linie nach rechts beginnt.
In der Sprache der relationalen Datenbanken bezeichnet man derart nicht-eingeschränkte Relationen als vom Typ m:n (o.ä.). Solche die links-eindeutig sein müssen als 1:n, rechts-eindeutige als m:1 und rechts- und links-eindeutige als 1:1.
Die rechts-eindeutigen Relationen sind von besonderer Wichtigkeit und bekommen einen eigenen Namen, sie heißen Funktionen oder Abbildungen. Es gibt auch meist einen eigenen Typkonstruktor, ähnlich wie
F = T -> U |
Abgesehen von der Rechtseindeutigkeit sind Abbildungen ganz normale Relationen,
können also rechts- und links-total sein, und links-eindeutig.
(Rechts-total heißt auch surjektiv und links-eindeutig heißt auch injektiv.)
Allemal geht aber von einem Element der linken Menge immer nur eine Linie aus!
Hier eine Reihe von Funktionen und ihre Eigenschaften:
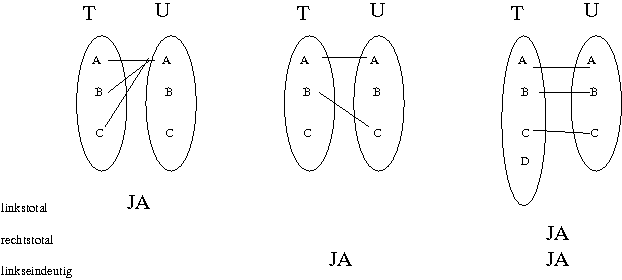
Es ist fast immer von inhaltlicher Bedeutung, ob eine Relation auch eine Funktion ist. Generell sollte eine Modellierung immer die Eigenschaften der Wirklichkeit engstmöglich nachbilden. Genau dadurch wird ein Modell ja bezgl. der realen Verhältnisse überhaupt erst aussagekräftig. Dabei muss man sich (andererseits) aber auch klar darüber sein, dass zukünftige Änderungen und Erweiterungen durch die Modellierung begrenzt werden.
Normalerweise ist die Relation "Person t arbeitet zur Zeit in Abteilung u" eine Funktion. D.h. jede Person hat maximal eine Abteilung, in der sie arbeitet. Soll das nicht gelten, so ist das eine gewisse Ausnahmesituation der Wirklichkeit. Diese spiegelt sich in Ausnahmesituation des Modelles, dass nämlich die entsprechende Relation nicht als Funktion "n:1" sondern als der Allgemeinfall "m:n" deklariert werden muss.
Den Relationen liegen (in der menschlichen Anschauung und psycho-internen Modellbildung)
symmetrische Vorstellungen zugrunde; die rechte und linke
Seite sind im Prinzip gleichberechrtigt. Bei den Funktionen kommt aber häufig eine
ganz andere Verwendungs- und Betrachtungsweise ins Spiel, die eines Fragen beantwortenden
Orakels: wir kennen einen Wert aus der Menge T und die Funktion gibt uns den
"dazugehörigen" Wert aus der Menge U. In dieser Betrachtungsweise sind rechte und linke
Seite unterschiedlich.
(Die Datentypen und Wertebereiche bekommen deshalb sogar eigene Namen und
heißen links Definitionsbereich oder
domain und rechts Wertebereich oder range.)
Diese verschiedenen Betrachtungsweisen haben auf die rein mathematischen Gegebenheiten übrigens keinerlei Auswirkungen; sie betreffen nur unseren Umgang mit den Daten.
Eine (zweistellige) Relation ist (als eine solche) immer umkehrbar: man vertauscht die
Komponenten aller Tupel und die Datentypen in der Typdefinition.
Ihre Bedeutung bleibt dieselbe.
Ein Funktion ist somit als Spezialfall der Relation auch immer in diesem Sinne umkehrbar.
Man nennt sie allerdings (als Funktion) umkehrbar nur dann, wenn diese umgekehrte
Relation auch wieder eine Funktion ist.
Da das einzige Kriterium dafür die Rechtseindeutigkeit ist, folgt daraus, dass jede
linkseindeutige Relation als Funktion umkehrbar ist.
Die Umkehrung einer Funktion, die nicht linkseindeutig ist, kann aber doch als Funktion
aufgefasst werden, nämlich in den Potenzmengen-Typ
"U -> POW T".
Dies ist ein sehr häufiger Fall.
Jedem Element auf der rechten Seite entsprechen ja u.U. mehr als ein Element auf der linken,
die Umkehrung wäre also keine Funktion. Liefert man aber die Menge dieser Elemente
zusammengefasst als ein(1) Ergebnis, dann ist die Relation wieder eine Funktion,
die halt nicht mehr ein einzelnes Element liefert, sondern eine Menge.
Dass dies sinnvoll sein kann zeigt die Frage nach den Mitarbeitern in einer Abteilung. Wenn diese als Funktion "angehörig" definiert werden soll, was ja zur Ausführung einer Abfrage die natürliche Modellierung ist, dann ist diese vom Typ
angehörig : abteilung -> POW person. |
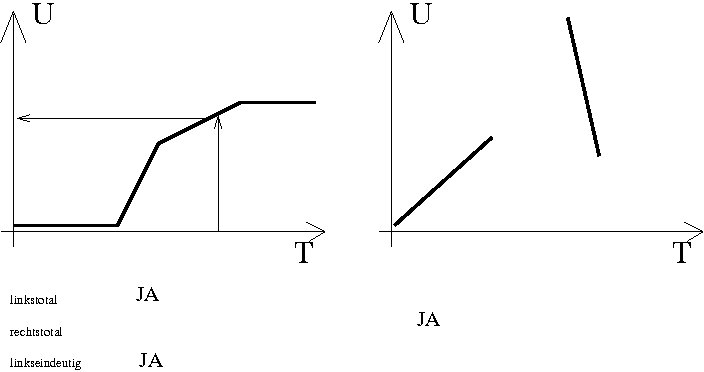
Funktionen gibt es häufig auch im kontinuierlichen Bereich.
Man visualisiert sie häufig als Kurven im Kartesischen Koordinatensystem.
Der Definitionsbereich T entspricht der horizontalen x-Achse, der Wertebereich U
entspricht der vertikalen U-Achse. Das Nachschlagen eines Wertes
(= in mathematischer Sprechweise die "Anwendung der Funktion") geht von einem Wert
aus dem Definitionsbereiche
T vertikal bis man die Kurve trifft, und dann horizontal zum Wertebereich U.
Dies ist in folgender Graphik angedeutet.
Als Funktionen sind sie rechtseindeutig, aber linkseindeutig, linkstotal und rechtstotal können gelten oder nicht, und sind definiert wie oben, siehe die beiden Beispiele in der Graphik.
Wichtige kontinuierliche Funktionen sind streng monoton steigend, dh. immer wenn der Ausgangswert steigt steigt auch der Funktionswert. (Bei (nicht-streng) monton steigenden Funktionen kann er auch gleichbleiben.)
Als letzte sehr häufige Sonderform sei zu erwähnen die Liste oder Sequenz.
Die Elemente des Wertebereiches des Datentypes "SEQ U" sind endliche Listen von Elementen aus
U. Auch diese können als Relationen begriffen werden, sogar als Funktionen, wobei
der Definitionsbereich T ein endlicher Präfix der natürlichen Zahlen ist, der genauso
lang ist wie die Liste.
Normalerweise sind diese Nummern auf der "linken Seite der Funktion" implizit und
entsprechen den Positionsnummern der Elemente in der Liste.
Man beachte dabei welche Positionsnummer das "linkeste Element" der Liste erhält:
meist ist dies der Indexwert "0" (null).
Systeme die mit "1" (eins) beginnen gibt es auch, aber sie sind deutlich seltener.
Die Eigenschaften rechtstotal und linkseindeutig, wie oben definiert, bleiben sinnvoll
und können vorliegen, oder auch nicht.
Sind beide Eigenschaften erfüllt so ist die Liste eine Permutation von U.
Diese modellieren z.B. einen Zieleinlauf eines Rennens, oder das
Ergebnis eines "Rankings".
An einem Beispiel zusammenfassend dargestellt:
s1, s2, s3: SEQ mitarbeiter // ie. spezielles "N -> mitarbeiter"
// linkseindeutig rechtstotal
s1 = < A, A, C, C> // nein nein
= { (0,A),(1,A),(2,B),(3,B) }
s2 = < A, C> // JA nein
s3 = < A, C, B> // JA JA
|
Ein weiterer, leicht komplexer Bereich von Modellierungsmitteln besteht
in Sprachen, Syntax und Semantik.
Dieser spielt die fundamentale Rolle bei allen Interaktionen von
Menschen mit technischen Systemen. Bei z.B. Datenbank-Anfragen die in
einer bestimmten "Sprache", wie noch zu definieren, abgefasst werden müssen, ist das
offensichtlich. Aber grundsätzlich können alle Abfolgen von
sehr verschiedenartigen Handlungen, für deren Aufeinanderfolgen bestimmte Regeln
definiert sind, als "Sprachen" betrachtet werden.
(Das wird daran sichtbar werden, dass der Begriff des Automaten in diesem Bereich
unzerzichtbar ist.)
Wir werden im folgenden auf diese "Anführungszeichen" verzichten, müssen aber immer im Hinterkopf behalten, dass der Begriff "Sprache" in Linguistik, Literaturwissenschaft, Jurisprudenz, Humanmedizin etc. etwas je eigenes und etwas fundamental anderes ist als der im folgenden dargestellte informationstheoretische. Dieser ist sehr eng und beschränkt in seiner Definition, also keinesfalls in der Lage, von sich aus all die Aspekte all der anderen wiederzugeben. Allerdings hat er den wertvollen Vorteil von sehr einfacher und präziser Definition und überraschend weiter Anwendbarkeit.
Eine Sprache im Sinne der Informationstheorie kann wie folgt beschrieben werden:
s : S = POW SEQ Σ |
Jede Sprache s über Σ kann also als einfaches Prädikat gesehen werden: Ein bestimmtes Wort über Σ gehört entweder zu der Sprache, oder nicht.
Wichtig ist, wie immer, dass die Definition des zugrundeliegenden Alphabetes Σ völlig abstrakt ist: Gefordert ist ledigliche eine endliche Menge von unterscheidbaren Objekten, Das können einzelne Zeichen eines Tastatur-Zeichensatzes sein, oder aber ganze Wörter einer menschlichen Sprache, oder unterscheidbare Gesten, oder Farben, oder Kraftfahrzeuge, die auf einem großen Parkplatz in eine Reihe manövriert werden können.
Dieses Kriterium, ob ein Wort zu einer Sprache s gehört oder nicht, ist exakt
eine "extensionale" Definition dieser Sprache.
Diese Definition ist gleichbedeutend mit der Syntax der Sprache: "syntaktisch
wohlgeformt" ist ein Wort über Σ dann, wenn es zu s gehört.
Diese Syntax wird aber i.A. nicht extensional definiert (was im Falle von unendlich großen Wortmengen ja gar nicht möglich ist), sondern durch Mechanismen der Syntaxdefinition. Im Bereich der Definition von Informationsverarbeitenden Systemen sind zwei grundlegende Mechanismen in Anwendung: Reguläre Ausdrücke und Kontextfreie Sprachen.
Beides sind Formalismen, die es erlauben, a priori strenge Aussagen über das spätere Verhalten der definierten Sprachen zu treffen. Dies ist eine ihrer wichtigsten Eigenschaften. So kann mit mathematischen Mitteln anhand des Definitionstermes für s schon entschieden werden z.B.
Viele dieser Fragen sind nicht mehr beantwortbar, wenn man mächtigere Werkzeuge zur Sprachdefinition verwendet, siehe als Beispiel unten Abschnitt 2.4.7 ("Semantische Prädikate ")
Für beide Formalismen existieren automatische Code-Generierungen, die aus der formalen
Spezifikation automatisch ablauffähige Programme generieren, die es erlauben, ein
Wort der Sprache als solches zu erkennen und zu analysieren.
Beide Formalismen sind also die theoretische Grundlage für viele
konkrete kommerzielle oder akademische Programmier-Werkzeuge in der täglichen Praxis,
und ihre Anwendung ist unverzichtbare Grundlage in fast allen Bereichen der
automatischen Informationsverarbeitung, -- zumindest allemal omnipräsent, um
die einleitenden Übersetzugsschritte durchzuführen für die
Abarbeitung von Benutzerbefehle, Konfigurationsdaten, Programmquelltext,
Datenbankanfragen, etc.
(Dieses Erkennen und Analysieren von Eingabesätzen heißt übrigens oft "Parsieren"; die gegenteilige Aufgabe, Sätze einer Sprache zu synthetisieren, ist in der Praxis seltener, aber theoretisch nicht komplizierter.)
In all diesen praktischen Fällen werden allerdings meist spezialisierte und/oder erweiterte Varianten der Grund-Formalismen implementiert. Auch hier ist es es aber wieder wertvoll und tröstlich zu wissen, dass diese Variantenbildung zwar der Benutzungsbequemlichkeit dient, i.A. aber nichts zu dem tasächlichen Leistungsumfang hinzufügt, so dass auch die Beschäftigung mit den einfacheren Varianten erlaubt, das Prinzip voll zu verstehen.
Ein regulärer Ausdruck kann betrachtet werden als ein "Wort einer Meta-Sprache", das eine Sprache beschreibt. Diese Meta-Sprache enthält einerseits die Symbole des Alphabetes Σ, also dieselben Elemente wie die zu definierende Sprache. Dazu kommen eine Menge von Operatoren (auch genannt Konstruktoren), die festlegen, wie diese Symbole zusammengefügt werden müssen, um ein syntaktisch gültiges Wort der Sprache zu beschreiben.
Es gibt sehr viele verschiedene Varianten von diesen Formalismen. Aber ein einfacher reicht, das Prinzip zu verstehen. Dabei ist fundamental, dass alle Varianten gleich mächtig sind. Die Menge der "regulären Sprachen" ist die Menge der Sprachen, die mit dem Mechanismus des "regulären Ausdrucks" beschreibbar sind, und diese ist unabhängig von der gewählten Variante der Schreibweise. Es sind halt nur bestimmte Konstruktionen bequemer hinschreibbar, siehe Beispiel am Ende des Abschnittes.
Nehmen wir also eine sehr einfache Variannte mit den Konstruktionen ...
s ( e ) e | e e, e e? e* |
Dabei stehe "s" für ein beliebiges Symbol aus dem Alphabet Σ. Es stehe "e" für einen beliebigen regulären Ausdruck, der mit diesen Konstruktionen gebildet werden kann.
Eine fundamentale Eigenschaft derartiger Systeme ist nämlich immer die freie Kompositionalität: Jeder noch so komplexe Ausdruck kann überall eingesetzt werden, wo auch eine einfache Referenz auf ein einfaches Symbol steht. Oder anders herum gesehen: Die Bedeutung eines jeden Ausdruckes ist nur durch seine Form bestimmt; der Kontext in dem er auftritt hat darauf keinen Einfluss und kann ein beliebiger sein.
In diesem Sinne ist die Klammerung "( e )" also nur eine Hilfskonstruktion, um einen zusammengesetzten Ausdruck als Einheit zu behandeln und die Priorität der innen und außen auftretenden Konstruktoren gegenseitig klarzustellen.
Die Bedeutung eines regulären Ausdruckes ist eine (reguläre) Sprache s, d.h. er definiert die Syntax dieser Sprache, also die Menge der in ihr enthaltenen Worte aus SEQ Σ. Dies kann man sich anschaulich so vorstellen, dass der reguläre Ausdruck ein "Rezept" ist, aus dem man durch Anwendung von Transformationsregeln alle Worte aus s ableiten kann. Genau dann, wenn eine solche Ableitung möglich ist, ist ein Wort in s, sonst nicht.
Im Laufe dieser Ableitung müssen selbstverständlich die Konstruktoren/Operatoren aus dem Regulären Ausdruck entfernt werden, da diese ja nicht in Σ enthalten sind, also auch nicht in einem Wort der Sprache. In den auf ihnen anwendbaren Transformationsschritten besteht ihre universelle Wirkung zur Definition aller möglichen regulären Sprachen.
Im einzelnen gilt:
Ein Ausdruck der Form "e | f" bedeutet eine Alternative und kann durch
den Teil-Ausdruck e oder den Teil-Ausdruck f ersetzt werden.
Ein Ausdruck der Form "e, f" bedeutet eine Reihung: beim Übergang auf
ein Wort der Sprache wird das Komma einfach weggelassen. (Man kann es auch im Formalismus
selber schon weglassen; es gibt, wie gesagt, sehr viele leicht unterschiedliche
Varianten des Formalismus!-)
Ein Ausdruck der Form "e?" bedeutet eine Option: der Ausdruck
e kann in ein Teil-Wort des zu konstruierenden Wortes transformiert werden.
Er kann aber auch vollständig weggelassen werden.
(In mathematischer Sprache sagt man dafür,
dass er dann in das o.e. "leere Wort" EPS transformiert wird.)
Ein Ausdruck der Form "e*" bedeutet eine Wiederholung: der Ausdruck
e kann ganz weggelassen werden, oder beliebig aber endlich oft hintereinandergeschrieben
werden.
Diese einfachen Konstruktoren sind ausreichend um den überraschend mächtigen Bereich
der Regulären Sprachen zu konstruieren.
Dies liegt nicht zuletzt an der bereits oben erwähnten "Freien Kompositionalität":
Reihung, Alternative, Option und Wiederholung beziehen sich ja auf beliebige
Ausdrücke, die einfache Symbole aus Σ sein können, aber auch
wiederum beliebig tief geschachtelte Konstruktionen.
Interessant ist, dass die Anzahl der Worte, die aus einem gegebenen Regulären Ausdruck
ableitbar sind, von den Operatoren ? und * abhängen: Die Option verdoppelt
die Anzahl der Möglichkeiten, wegen der Ja-Nein-Entscheidung, der Stern-Operator
hat unendlich viele (jeweils endliche lange) Expansionen.
Einige Beispiele für Reguläre Ausdrücke und mögliche Expansionen, wobei s, t, u für Symbole aus dem Alphabet Σ stehen, und EPS für das leere Wort:
s, t, u --> s t u
s, t?, u --> s t u
--> s u
s, (t | u) --> s t
--> s u
(s|t)*, t --> t
--> s t
--> t t t t t
--> t t s t t
--> // unendlich viele weitere
(s*, t, u)* --> EPS
--> t u
--> t u t u
--> s s s s s s s t u t u
--> t u s t u
--> // unendlich viele weitere
|
Bei den Varianten dieses Formalismus ist die häufigste Ergänzung der "+" Operator. Dieser steht auch für beliebige Wiederholung, aber mindestens einmaliges Auftreten. Dass eine Variante die Ausdrucksfähgikeit des Formalismus (also die Menge der beschreibbaren Sprachen) nicht erhöht, zeigt sich daran, dass er bedeutungswahrend durch eine andere Schreibweise ersetzt werden kann:
e+ --> e, e* |
Auch gibt es Varianten, die mit der Konstruktion e{m,n} noch genauere Angaben
erlauben, nämlich wieviele Wiederholungen minimal und maximal erlaubt sind, wobei
die Obergrenze auch weggelassen werden kann.
All diese Varianten vereinfachen nur das Hinschreiben, fügen aber keine Ausdruckskraft hinzu,
was wiederum die bedeutungswahrende Ersetzung beweist:
e{3,6} --> e, e, e, e?, e?, e?
oder --> e, e, e, (e, (e, e?)?)?
e{3,} --> e, e, e, e*
|
Wichtige Eigenschaften der Reguläre Ausdrücke und der Regulären Sprachen sind ihre leichte Verständlichkeit und Übersichtlichkeit für den menschlichen Leser und ihre leichte Implementierbarkeit für die maschinelle Ausführung. Die Regulären Sprachen entsprechen nämlich Eins-zu-Eins den sog. "Deterministischen Endlichen Automaten" = "DEA" = englisch "DFA", einem sehr einfachen Modell von maschinellem Verhalten.
Auch von diesen DEA gibt es eine Fülle von Varianten und Erweiterungen. Es reicht aber wieder eine sehr grundlegende Form, um das Prinzip zu verstehen und anwenden zu können.
Als formale Definition kann getroffen werden
DEA = Σ:given * S:given * (i ∊ S) * (F ∊ POW S) * (Q: S*Σ -/-> S) |
Diese Formel beschreibt den "Typ DEA", also die "Menge aller möglichen DEAs".
Betrachten wir ihre Bedeutung an einem Einzelfall:
Ein bestimmter DEA besteht aus einem Alphabet Σ, wie auch oben für die Definition
einer Sprache benötigt. Daneben aus einer Menge S von Zuständen,
aus einem ausgezeichneten initialen Zustand i und aus einer Menge von
ausgezeichneten akzeptierenden (oder finalen) Zuständen F.
Zuletzt gibt es die Übergangsfunktion Q, die einem Paar aus Zustand und
Symbol des Alphabetes einen neuen Zustand zuordnet, oder auch nicht.
(Partielle Funktion durch das Zeichen "-/->" angezeigt.)
Dies alles wird sehr viel einfacher und verständlicher, wenn man sich einer konkreten Vorstellung bedient: Der Automat ist in jedem Zeitpunkt in einem bestimmten Zustand aus der Menge S. Wenn er dann "ein Eingabezeichen empfängt", das aus dem Alphabet Σ stammt, macht er einen Übergang in einen anderen Zustand, wie es durch Q vorgeschrieben ist. Man sagt, er "akzeptiert das Zeichen". Wenn Q für diese Kombination von Zustand und Zeichen keinen Übergang definiert, dann "blockiert" der Automat, stellt jede weitere Tätigkeit ein, und die Eingabe als Ganze wird "zurückgewiesen".
Bevor er das erstes Zeichen erhält wird der DEA in den Initialzustand i versetzt. Nachdem er das letzte Zeichen erhalten hat, muss er in einem der akzeptierenden Zustände aus F sein, damit die Eingabe als Ganze akzeptiert wird.
Es zeigen sich nun für die konkrete Modellierungspraxis drei wichtige Tatsachen:
(Letzteres ist auch der Grund, warum sie hier im Rahmen dieser allgemeinen Einführung nicht ausgelassen werden können.)
Noch einfacher wird das Verständnis mit der Standard-Visualisierung.
Dabei sind die Zustände Kreise in einem Graph, die möglichen Übergänge sind Pfeile
dazwischen, beschriftet mit dem jeweils akzeptierten Zeichen, und die akzeptierenden
Zustände und der initiale Zustand werden auch graphisch gekennzeichnet.
Ein einfaches Beispiel:
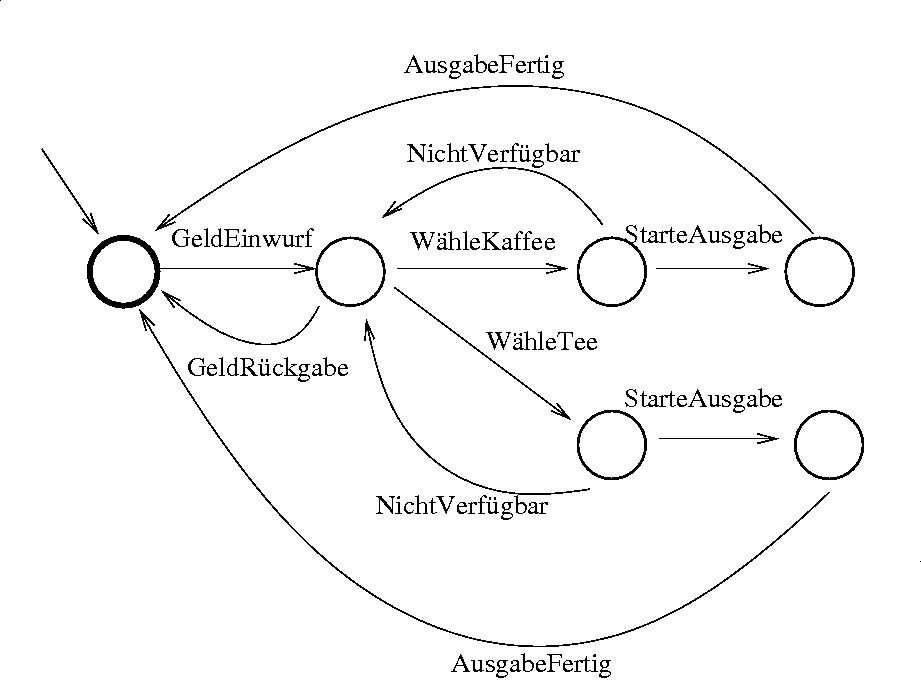
Man sieht das Modell des Verhaltens eines einfachen Getränkeautomatens: Der von außen kommende Pfeil zeigt auf den initialen Zustand. Die Symbole des Alphabetes sind die Handlungen des Kunden und des Automaten:
Σ = { GeldEinwurf, GeldRückgabe, WähleKaffee, WähleTee,
NichtVerfügbar, StarteAusgabe, AusgabeFertig }
|
Der einzige akzeptierende Zustand (dargestellt durch den dickeren Rand) ist auch der initiale. Das heißt, erst wenn ein Zyklus vollständig durchlaufen ist: Geld eingeworfen, Getränk gewählt und erhalten, oder Geldrückgabe angefordert, -- erst dann ist der Automat wieder im Ausgangszustand, und die Sequenz von Handlungen (= von Symbolen des Alphabetes Σ) ist als ein "syntaktisch gültiges Wort der Eingabesprache" akzeptiert.
In einer solchen graphischen Visualisierung wird auch anschaulich, was das "deterministisch" im Namen DEA bedeutet: Aus jedem Zustand führt für jedes Zeichen des Alphabetes maximal ein Pfeil heraus, der damit beschriftet ist. Das Fortschreiten von einem Zustand zum nächsten ist also für jedes Eingabezeichen eindeutig bestimmt. (In dem mathematischen Typausdruck oben ist das darin ausgedrückt, dass Q eine Funktion ist!)
Man kann an diesem einfachen Beispiel schon sehen, welche Erweiterungen sinnvoll wären:
Komplexere Formalismen wie die "Statecharts" von Harel ([harel]) bieten u.a. solche Erweiterungen. Auch die de-facto-Standards wie "Business Process Modelling Language", "Business Process Model and Notation" und andere Modellierungssprachen speziell für Geschäftsprozesse, Dokumentenmanagement, Online-Prozesse, etc. (siehe [gur]) bauen grundsätzlich alle auf dem Prinzip der DEAs auf. Allerdings werden dabei viele spezialisierte Formalismen und Abstraktionsmechanismen dazugepackt; man erkauft dann die bequemere Formulierbarkeit um den Preis der deutlich schlechter überschaubaren und teilweise auch nicht hinreichend präzise spezifizierten Semantik.
Die wichtige Äquivalenzeigenschaft von DEA und Regulären Sprachen besagt in der
einen Richtung, dass die maschinelle Erkennung von syntaktisch korrekten Sätzen von
Regulären Sprachen sehr einfach und effizient zu implementieren ist, da DEAs in der
Ausführung sehr effektiv implementierbar sind.
Es sagt andererseits, dass das Verhalten eines jeden DEA als Regulärer Ausdruck
beschreibbar ist. Im Falle obigen Beispiels ist jeder Zyklus vom initialen zu
einem akzeptierenden Zustand ein Wort der Sprache, die definiert werden kann durch
Getränkeautomat = Geldeinwurf, ( (WähleKaffee, NichtVerfügbar) |
(WähleTee, NichtVerfügbar) )*,
( ((WähleKaffee | WähleTee), StarteAusgabe, AusgabeFertig)
| GeldRückgabe)
|
Hier wird wieder sehr schön deutlich, dass Modellierung ímmer nur bestimmte
Teilaspekte der Wirklichkeit wiedergeben kann und soll:
Der Vorgang der Geldrückgabe könnte wie die Getränkeausgabe mit zwei Zuständen und
zwei Symbolen des Alphabetes modelliert werden.
Weiterhin ist in unserem DEA nicht ausgeschlossen,
dass der Benutzer mehrfach den Zyklus "(WähleKaffee, NichtVerfügbar)*" durchläuft,
um dann plötzlich doch Kaffee zu erhalten, -- ein Verhalten, das nicht von
allen Getränkeautomaten zu erwarten ist.
Die Ausdrucksfähigkeit von Regulären Sprachen und DEAs reicht allerdings nicht aus,
beliebig komplexe Sprachen zu definieren, also beliebige Teilmengen der
Menge aller Worte über dem gegebenen Alphabet Σ.
In der Tat gibt es die berühmte "Chomsky-Hierarchie", die vier verschiedenen
Komplexitätsklassen von Sprachen definiert [chomsky].
Von diesen sind die Regulären die einfachsten, nummeriert als "Typ drei".
Für die Analyse und Definition der meisten Informationsverarbeitenden Systeme
reicht es, sich mit der nächst-komplexen Klasse zu beschäftigen,
den kontextfreien Sprachen.
Z.B. gehören sämtliche "Programmier-Sprachen" in jedwedem Sinne zur den regulären
oder den kontextfreien Sprachen.
(Nicht jedoch reichen diese beiden Klassen aus zur Analyse von
menschlich-natürlicher Sprache, was aber im Sinne dieses Artikels als
anwendungsspezifisch aufgefasst wird, jenseits der hier betrachteten allgemeinen Grundlagen.)
Kontextfreie Sprachen werden so oder ähnlich modelliert:
L = N:given * start:N * Σ:given * P: N -> POW SEQ (N u Σ) |
N ist eine gegebene Menge von Non-Terminalen. Σ ist wieder das Alphabet der zu beschreibenden Sprache. Die Symbole aus Σ werden in diesem Zusammenhang meist Terminale (Symbole) genannt. P ist die Menge der Produktionsregeln. Die Produktionsregeln ordnen jedem Non-Terminal-Symbol eine oder mehrere Folgen zu, jede beliebig gemischt aus Terminal- und Non-Terminal-Symbolen.
Der Ableitungsprozess eines Wortes der Sprache besteht darin,
ein "aktuelles Wort" aus dem Alphabet "N u Σ" (also Terminale und Non-Terminale
beliebig gemischt) schrittweise in ein Wort der Sprache über Σ zu überführen.
Jeder Ableitungsschritt verändert das aktuelle Wort in ein neues aktuelles Wort,
in dem ein beliebiges im aktuellen Wort auftretendes Non-Terminal gemäß
einer entsprechenden Regel aus P durch deren rechte Seite ersetzt wird.
Man beginnt dabei immer mit dem einstelligen Wort, das nur das Startsymbol start enthält.
"Am Ende" jedes solchen Ableitungsprozesses sind nur noch Symbole aus Σ im Wort enthalten,
-- deshalb die Bezeichnungen "non-terminal" und "terminal".
Im folgenden Beispiel sind, wie oft üblich, die Terminalen Symbole in Anführungszeichen. Das Startzeichen sei start.
start ::= ausdruck // Regel 1
ausdruck ::= "(" ausdruck ")" // Regel 2
ausdruck ::= "a" // Regel 3
ausdruck ::= "b" // Regel 4
ausdruck ::= ausdruck operator ausdruck // Regel 5
operator ::= "+" // Regel 6
operator ::= "-" // Regel 7
operator ::= "*" // Regel 8
operator ::= "/" // Regel 9
Eine mögliche Ableitung:
start // Regel 1
--> ausdruck // Regel 5
--> ausdruck operator ausdruck // Regel 2
--> ausdruck operator "(" ausdruck ")" // Regel 3
--> "a" operator "(" ausdruck ")" // Regel 5
--> "a" operator "(" ausdruck operator ausdruck ")"// Regel 6
--> "a" "+" "(" ausdruck operator ausdruck ")"// Regel 4
--> "a" "+" "(" ausdruck operator "b" ")"// Regel 3
--> "a" "+" "(" "a" operator "b" ")"// Regel 8
--> "a" "+" "(" "a" "*" "b" ")"
= "a+(a*b)"
|
Obwohl dieses Beispiel nicht komplex ist, erkennt man sofort die über die Regulären Ausdrücke hinasugehende Mächtigkeit: Die ausgewogenen Klammerungen können mit diesen nämlich nicht dargestellt werden, -- die Regulären Ausdrücke "können sich nicht merken, wie oft in der Vergangenheit eine Klammer geöffnet wurde". Die Kontextfreien Sprachen können das, weil wie in Regel 2 z.B. an mehr als einer Stelle gleichzeitig ein Symbol aus Σ in das Wort eingesetzt wird, und danach an beliebigen Stellen mit dem Ersetzungsprozess weitergemacht werden kann.
Weil dieser Formalismus "mächtiger" ist (es können mehr Sprachen mit ihm definiert werden),
kann er auch nicht mehr mit DEAs einfach realisiert werden. Vielmehr muss ein "Keller-Automat"
verwendet werden, ein Automat, der zusätzlich zu seinen Zuständen noch ein "Gedächtnis" hat.
Die Theorie und Praxis derartiger Automaten überschreitet den Horizont dieser allgemeinen
Einführung. Es ist aber dennoch tröstlich zu wissen, dass es Programm-Generatoren gibt,
die formale Spezifkationen einer kontextfreine Sprache automatisch in ein ausführbares
Computerprogramm übersetzen, was auf dem Prinzip des "Keller-Automaten" basiert.
Die Regulären Sprachen. also die des einfacheren Chomsky-Typs "drei" sind alle in den Kontextfreien Typ-zwei Sprachen enthalten. Das erkennt man leicht daran, dass die Kontruktoren der oben verwendeten Varianten für Reguläre Ausdrücke bedeutungserhaltend durch Regeln im stärkeren Formalismus ersetzt werden können:
x = a? ==> x ::= a
x ::= EPS
x = a* ==> x ::= a x
x ::= EPS
x = a|b ==> x ::= a
x ::= b
|
Vice versa erlauben die meisten der in der Praxis angewandten Varianten der Kontextfreien Sprachen, auf den rechten Seiten der Regeln aus "P" nicht nur einfache Folgen von (Σ u N) hinzuschreiben, sondern sogar reguläre Ausdrücke darüber. Dies ändert ja nichts an der Ausdrucksfähigkeit, da man vorstehende Äquivalenzen auch rückwärts anwenden könnte.
Der Schreibaufwand wird deutlich geringer und das Ergebnis übersichtlicher, wie die Transformation der obenstehenden Regeln zeigt:
start ::= ausdruck
ausdruck ::= "(" ausdruck ")"
| "a" | "b"
| ausdruck operator ausdruck
operator ::= "+" | "-" | "*" | "\"
|
In der Modellierungspraxis kann eine Formulierung als Kontextfreie Sprache auch dann sinnvoll sein, wenn das Ergebnis nur eine Reguläre Sprache ist, allein deshalb, weil der Formalismus verständliche Namen für Teilausdrücke vorsieht, die eine selbst-dokumentierende Funktion ausüben können, und im Formalismus "Reguläre Ausdrücke" normalerweise nicht vorgesehen sind:
Aktenzeichen ::= Dienstelle Abteilung "-" LfdNummer "/" Jahr
Dienststelle ::= "Js" | "MfJ"
Abteilung ::= ("I" | "II" | "III" | "IV" ) Dezimalziffer
LfdNummer ::= Dezimalziffer Dezimalziffer*
Jahr ::= Dezimalziffer Dezimalziffer
Dezimalziffer::= "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9"
---> ist identisch mit dem regulären Ausdruck
Aktenzeichen ::= ("Js" | "MfJ") ("I" | "II" | "III" | "IV" )
("0"|"1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9")
"-"
("0"|"1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9")
("0"|"1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9")*
"/"
("0"|"1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9")
("0"|"1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9")
|
Die rein informationstheoretische Betrachtung von Sprachen ist, wie oben erwähnt, zweifellos immer ein starke Beschränkung der unzähligen Aspekte von Sprache im allgemeinen. Ihre größten Vorteile sind (a) die vielen voraus-berechenbaren Eigenschaften der durch sie definierten Sprachen, s.o. Abschnitt 2.4.2 ("Definitionen von Syntax"), und (b), dass es einen vergleichsweise einfach zu konstruierenden und sehr präzisen Begriff von Semantik gibt.
Die Konstruktion einer solchen Semantik funktioniert grundsätzlich so:
Im Falle unseres Getränkeautomaten kann der Datentyp des Zustandsraumes als Produkt modelliert werden:
w: W = geld:N * kaffe:N * tee:N * teeGewählt:bool |
wobei die drei Zahlen den Zustand des Geld-, Kaffee- und Tee-Speichers des Automaten darstellen. Der Zustand würde bei einem Besuch des Service-Technikers, nach Abholen allen Geldes und Auffüllen der Vorräte z.B. auf w = (0, 100, 200, _) initialisiert werden.
Die Übergänge an den Pfeilen in obiger Automaten-Graphik werden dann ergänzt um die Modifikationen der entsprechenden Komponenten dieses Produktes w. Dabei wird auf den Vorzustand mit Variablen bezug genommen. Der Einfacheit halber können Variablen, die sich nicht ändern, oder die nicht gelesen werden, durch einen "Don't-Care"-Platzhalter wie "_" markiert werden.
Die Pfeile(=Übergänge) des obigen Getränkeatomaten wirken auf den semantischen Zustand wie folgt:
GeldEinwurf GeldRückgabe
----------------> --------------->
(g,_,_,_) (g+1,_,_,_) (g,_,_,_) (g-1,_,_,_)
WähleKaffee WähleTee
----------------> ---------------->
(_,_,_,_) (_,_,_,false) (_,_,_,_) (_,_,_,true)
AusgabeFertig NichtVerfügbar
----------------> StarteAusgabe
(_,k,_,false) (_,k-1,_,_) ----------------->
oder // keine Auswirkung in der Semantik
(_,_,t,true) (_,_,t-1,_)
|
Bis hierhin ist die Semantik-Konstruktion lediglich eine zusätzliche Interpretation
der ohnehin akzeptierten Worte. Worte, die schon syntaktisch "nicht korrekt" sind, also überhaupt
nicht zur Sprache gehören, fallen auch nicht unter die Definition einer solchen
Semantik.
Dies ist eine in der Praxis höchst wichtige Regel, die oft wissentlich verletzt wird!
So werden z.B. nicht-wohl-geklammerte HTML- oder XHTML-Texte von vielen Browser-Programmen
"irgendwie und annäherungsweise doch noch optisch dargestellt",
obwohl streng genommen noch nichteinmal
die Syntax-Definition der Eingabe erfüllt ist, geschweige deren Semantik definiert.
Dieses Vorgehen wird von vielen in Theorie und Software-Technik
nicht hinreichend geschulten "Hackern" als hinreichend
angenommen. Es bietet jedoch keinerĺei Gewähr, dass dies auch fürderhin
immer so funktioniert, geschweige denn einklagbar verlangt werden kann.
Die Argumentation, es sei berechtigt,
außerhalb der spezifizierten Syntax zu arbeiten, ist vergleichbar
mit dem Satz "zwei plus zwei gleich drei Komma neun acht, --- jedenfalls war das bei
all unseren Anwendungsfällen bisher hinreichend genau."
Wenn es nur darum geht, eine Tabelle von Freizeit-Fotos
auf den Bildschirm zu bringen, mag diese Argumentation angehen, -- die "Ariane-Rakete"
ist aber durch ähnlich gelagerte Nachlässigkeit explodiert!
Deshalb sollte bei jeder Modellierungsdiskussion auf die ersten
zwei Punkte folgender Liste streng geachtet werden:
(a) Alle Syntaktischen Definitionen müssen strictissime eingehalten werden.
(b) Die Definition von Semantiken muss vollständig sein, d.h. alle syntaktisch
gültigen Worte müssen von der Semantikdefinition erfasst werden,
(c) Sie sollte aber auch nicht über-vollständig sein:
Für Worte über Σ, die nicht Worte aus der Sprache sind, sollte am besten gar keine
Semantik definiert sein, da diese wegen (a) ja eh nie zur Anwendung kommen darf und
den menschlichen Leser der Spezifikation nur verwirren würde.
Bis hierhin tangiert diese hinzugefügte, rein interpretierende Semantik in keiner Weise die Menge der akzeptierten Worte, also die Sprache selbst. Etwas deutlich weitergehendes, ja fundamental anderes sind dann allerdings die sog. semantischen Prädikate. Diese bestehen darin, dass umgekehrt aus dem semantischen Zustand nun Bedingungen für die Anwendbarkeit eines Überganges oder einer Ersetzungsregel abgeleitet werden. Dieser Erweiterung des Formalismus liegt scheinbar sehr nahe, da jetzt der Automat auf der semantischen Ebene ja "weiß", ob noch Kaffee-Portionen ausschenkbar sind:
StarteAusgabe NichtVerfügbar
----------------> ------------------>
(_,k>0,_,false) (_,_,_,_) (_,k==0,_,false) (_,_,_,_)
oder oder
(_,_,t>0,true) (_,_,_,_) (_,_,t==0,true) (_,_,_,_)
// alle anderen Pfeile wie oben
|
Semantische Prädikate sind eine in der Praxis sehr beliebte, praktische und mächtige Vorgehensweise, bedeuten aber einen grundlegenden Paradigmenwechsel, vor dem deutlich zu warnen ist: Man erkauft sich die Anwendbarkeit "beliebiger" Mathematik mit dem schlagartigen Verlust aller o.e. Vorhersagbarkeit und Berechenbarkeit, die ja einen großen Vorteil der einfachen rein-syntaktischen Formalismen darstellen, s.o. Abschnitt 2.4.2 ("Definitionen von Syntax").
Die genauere Kenntnis der Arbeitsweisen der verschiedenen Formalismen zur Definition von
Semantiken liegt außerhalb des Horizontes dieser Einführung und ist auch
für planerische Diskussion weitgehend entbehrlich. Wichtig ist allerdings die
Kenntnis der scharfen Grenze und des
fundamentale Unterschiedes zwischen den rein-syntaktischen Definitionen mit ihrer
Berechenbarkeit und Vorhersagbarkeit, aber eingeschränkten Ausdrucksfähigkeit,
gegenüber der "Büchse der Pandora" der ungebegrenzten Algebra und Arithmetik, die zwar
mehr erlaubt, aber in ihrem Verhalten nicht mehr berechenbar ist.
Gerade das kann aber z.B. bei Entwurf, Definition, Implementierung und Betrieb von
informationsverarbeitenden Systemen (im weitesten Sinne) durchaus praktische und
unangenehme Konsequenzen haben, die es vorauszusehen, abzuschätzen und zu begrenzen gilt.
Zu einer hinreichenden Qualifikation der "Kundenseite" in einer informationstheoretischen oder -technischen Modellierungs-Diskussion fehlen, was die allgemeinen, nicht fach-spezifischen mathematischen Werkzeuge angeht, u.E. nur noch zwei weitere statische Bereiche, nämlich Logik und Ontologien. Dazu kommen die grundlegenden "dynamischen" Mechanismen von Prozessalgebren und temporaler Logik. All dies muss einer Fortsetzung dieser Arbeit vorbehalten bleiben.
|
[Cantor]
Beiträge zur Begründung der transfiniten Mengenlehre in: Mathematische, pg.481, Berlin, Göttingen, Heidelberg, 1869 https://web.archive.org/web/20140423224341/http://gdz-lucene.tc.sub.uni-goettingen.de/gcs/gcs?&&action=pdf&metsFile=PPN235181684_0046&divID=LOG_0044&pagesize=original&pdfTitlePage=http://gdz.sub.uni-goettingen.de/dms/load/pdftitle/?metsFile=PPN235181684_0046%7C&targetFileName=PPN235181684_0046_LOG_0044.pdf& |
|
[Codd]
Relational Completeness of Data Base Sublanguages in: Database, pg.65, Prentice-Hall, Englweood Cliffs, NJ, 1972 |
|
[chomsky]
Three models for the description of language in: IRE, Vol.2, pg.113, World, 1956 doi:10.1109/TIT.1956.1056813 https://chomsky.info/wp-content/uploads/195609-.pdf |
|
[gur]
BPMN, BPEL, BPML and XPDL, an attempt to make some order in the business modeling jungle theWeb, 20070103 http://blogs.sap.com/2007/01/03/bpmn-bpel-bpml-and-xpdl-an-attempt-to-make-some-order-in-the-business-modeling-jungle/ |
|
[harel]
Statecharts: A visual formalism for complex systems. in: Science, Vol.8, pg.231, North-Holland, June 1987 |
|
[merkel]
Rede zur Deutsch-Französischen Digitalkonferenz am 13. Dezember 2016 Berlin, 2016 http://www.bundesregierung.de/Content/DE/Rede/2016/12/2016-12-13-deutsch-franzoesische-digitalkonferenz.html |
|
[spiveyZ]
The Z Notation --- A Reference Manual Prentice Hall International, Upper Saddle River, NJ, 1992 |
1 Typische derartige fundamentale Einschränkungen sind z.B.: Ein NP-Problem kann nicht in annehmbarer Zeit berechnet werden; relationale Algebren können keine transitive Hülle berechnen; keine Programmiersprache kann mehr als jede andere Turing-vollständige; etc.
made
2018-02-07_10h36
by
lepper
on
linux-q699.site


produced with
eu.bandm.metatools.d2d
and
XSLT